adobeio-runtime
I/O Runtime Quickstart Guide
Serverless platforms can solve a wide range of business requirements while greatly reducing the complexity associated with development and operations. However, in order to be successful, you need to consider the strengths of serverless platforms while also being mindful (and finding ways to work around) the limitations.
This quickstart guide explores the most critical of these considerations as they apply to I/O Runtime and includes information on the following topics:
- I/O Runtime Programming Model
- The Big Picture – Understanding I/O Runtime components
- Zoom In – What’s Happening When Actions Are Invoked
- Let’s Talk Numbers – Understanding the System Settings
- I/O Events Integration
- Strategies for High Availability Applications
- CI/CD Pipeline – What Is Available
- Security Considerations
- The Future is Bright - Cloud Native Applications
Programming Model
Namespaces, actions, packages, shareable, compositions and web actions/APIs
Developer can write the code in JavaScript and it will be executed by a Node.js environment. This means they can also use any of the available Node modules.
Code is organized in actions (just another name for function) and gets deployed in a namespace (a namespace is owned by one tenant, and a tenant can have multiple namespaces).
An action can be invoked via an HTTP call (RESTful call or HTTP call) or from another action. Actions can be chained together in order to create complex flows using sequences (single chain of action executed one at a time and the result being passed to the next one) or compositions (trees of actions where you can take a decision at each node what action to execute next).
Actions can be organized into packages. You can create as many packages you want inside of a namespace. You use packages to organize the code, manage different versions for the same action or to share the code with other tenants/applications. When you mark a package as shareable, anyone who has the full name, can bind that package to his own namespace (think of a symbolic link).
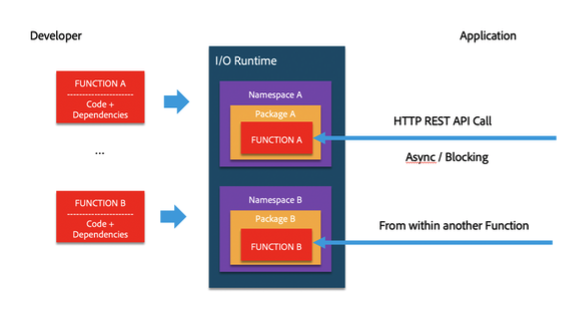
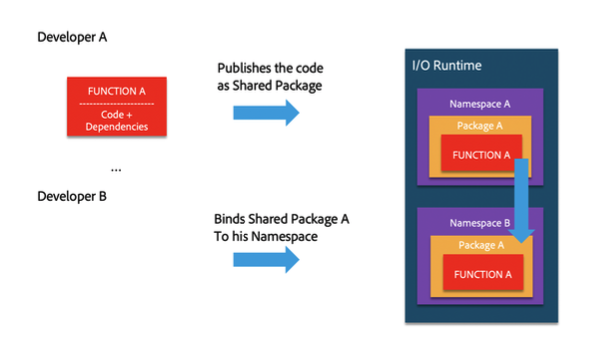
Actions can be invoked anonymously (no auth required) or with authentication. Out of the box we only support basic auth. Developers can implement their own auth. We will be adding support for IMS based auth.
The Big Picture – Understanding I/O Runtime components
Adobe I/O Runtime is built on top of an open source project called Apache OpenWhisk. Because of this, many of the resources written for Apache OpenWhisk also apply to Adobe I/O Runtime, making the Apache OpenWhisk repository another useful resource for you to reference.
The diagram below shows the high-level architecture of I/O Runtime built on top of OpenWhisk:
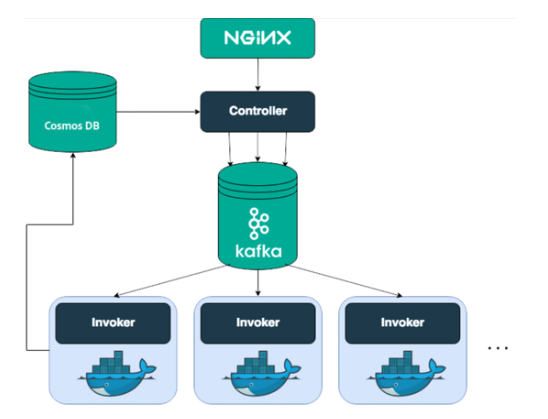
The whole purpose of the system is to execute the code the user has created. Let’s see what all these big components do when an action is executed:
- First, the nginx will receive the call that a specific action is invoked. Its role is mainly to perform SSL termination and forward the call to the Controller
- Controller performs tasks that disambiguates what the user is trying to do (invoke action X from namespace Y) and authenticate/authorize (verifies who is the caller and that is has the permissions to execute the code). AuthN/AuthZ is done against the Cosmos DB where information about users and namespaces are persisted.
- If all checks have passed, the Controller will load the action code and action settings (memory, default parameters) from the Cosmos DB/S3 and will schedule the execution with one of the available Invokers.
- This scheduling happens through Kafka: Controllers and Invokers communicate through Kafka messages. When an invocation request is persisted in Kafka, an ActivationId is issued to the client. This ID can be used to retrieve the result of the execution.
- The Invoker will take the action code and inject into a Docker container and then invoke the action. The result of the invocation is persisted in Cosmos DB under the same ActivationId.
The flow above describes what is happening inside of a cluster but we have multiple clusters, deployed in different regions. I/O Runtime is running in multiple Amazon regions today. We plan on adding Azure clusters in the future. We route a call to one of the clusters using latency-based routing – the cluster closest to the caller gets the request. Behind the scene, customer’s code is pushed transparently to all clusters.
Zoom In – What’s Happening When Actions Are Invoked
Let’s zoom in on what exactly happens when an action invocation request is accepted by I/O Runtime (ActivationId was issued). There are mainly two concepts that are relevant to a developer: activation lifecycle and container lifecycle - activation is our terminology for an action invocation and container is what is used to run the action.
Activation lifecycle:
- For async invocation (non-blocking) system returns 202 immediately with an ActivationId. Client will be using the ActivationId to pull the result
- For blocking invocations system returns either:
200and the result504and an activation ID will be available for debugging (see the error message and retrieve logs if any)
- In the case of invoking too many actions per minute, the requests are throttled and the system returns 429. It is the client responsibility to scale back and retry later, because the system is not buffering the request for later processing. See more about these limits in the next sections
Container lifecycle:
- When an action is invoked for the first time, a new container is created and the action code is injected in it. This is called a warm container
- A warm container is reused only for the same user and action version
- A warm container sits idle for 10 minutes. If no requests are received, it will be recycled
- The System maintains a pool of prewarm containers – these are containers created with the default Node version and a memory value of
256MB,512MB, or1024MBand can be used by any user and action. Once they are initialized for an action, they become warm containers - A cold start refers to a situation when the system is under load and has no prewarm or warm containers to use for the invocation. The request is buffered and the system will create a new container by either recycling an idle container or creating a new container
Let’s Talk Numbers – Understanding the System Settings
There are some system limits that influence your application design: https://github.com/AdobeDocs/adobeio-runtime/blob/master/guides/system_settings.md
Some of these are worth to be highlighted:
- Concurrent – this refers to how many activations can be submitted per a namespace. Regardless of how big this value is, if you try to execute 1 more than the maximum number you’d get a 429 error
- Concurrency per container – refers to how many activations can be executed in parallel for the same action in the same container. You want to use the biggest value that works for your code
- MinuteRate – it is about how many activations you can have in flight. Again, regardless of how big this number is, you will get throttled if you try more
- Payload/Result size – you can’t send inline data more than 1MB or return more than 1MB. If you need more, you should consider reading/writing from something like a S3 bucket
- Memory – the amount of RAM requested by your action
Note: If your organization cannot be served by the default values, the limits for minuteRate and concurrent settings can be raised. Please visit the Adobe I/O Runtime Forums for developer support.
I/O Events Integration
I/O Events exposes a number of Adobe events to 3rd-parties (the list is growing) – Analytics, Experience, Cloud Manager, GDPR, AEM, Data Ingestion and Real-Time customer profile events. An application can subscribe to these events (push model, consuming them via webhooks) or use journaling to retrieve the events (pull model).
In I/O Console a developer can choose the events and then send them to a webhook he has created in some other platform or select a Runtime Action to receive the event. Another option would be an action that reads the events using the Journaling API.
Strategies for High Availability Applications
While I/O Runtime is highly available and scalable compute platform, there are some application design considerations that any developer using I/O Runtime should take into consideration.
- Favor async calls. If your application can do with an async design, you should go for it. This gives a higher chance to execute the code instead of running in timeouts
- Responding to 429 status code. When your application is hitting the upper limit for throttling, you will get 429s. If you don’t scale back, you’d keep getting this answer
- Responding to 5xx status code. There are situations when your invocation will not come though (if this wasn’t the case, we would offer 100% uptime). If you can’t afford to lose an invocation, you should build a retry mechanism (at this time we don’t offer a retry mechanism). This can be built outside our platform, or you could use Runtime triggers feature to create an action that is executed every 40 minutes and performs the retry or does some logging in your system, so you can try again
- Minimizing chances for cold starts. If you care about low latency and high availability, then leverage the knobs we have to tune for this:
- Concurrency per container. Default value is 200 and it means that up to 200 invocations can be sent in parallel to the same container. You can set the value to 1 and that would mean that if you have 10 invocations in a second, you’d use 10 different containers. If your code initializes data (downloading data, creating an object) then this will happen only once. All the invocations sent to the same container don’t have to spend that time.
- Use the default RAM setting for your action. We keep a pool of prewarm containers that use the default RAM setting. Using a prewarm container is the next best thing after reusing a container
- Fan out. I/O Runtime is built to run lots of tasks in parallel. If you have a large task that can be split in multiple small tasks, you should do it. Otherwise you end up with an action that needs long time to execute and maybe lots of memory (this is bad, see the minimizing cold starts point).
Note: Work is in progress for providing persistence. This will greatly enhance a developer’s ability to build a retry mechanism or fan out/fan in.
CI/CD Pipeline – What Is Available
I/O Runtime doesn’t offer a complete CI/CD pipeline. Instead it offers the building blocks that can be used to create a pipeline. The reason for this is that CI/CD is still a new topic in the serverless world, including OpenWhisk (the project behind I/O Runtime), and different teams have different preferences. This is why we decided to postpone this effort and see where the market goes.
The components available for building a pipeline are:
- CLI tool that can be used to manage (deploy, update, delete) and invoke actions
- RESTful API that can be used to manage and invoke actions
- Namespaces and packages that can be used to create different environments (dev, qe, stage, production) and manage versions (different versions of the same action) Using these key ingredients, one can create a pipeline that uses Jenkins or CI/CD or anything in between.
Security Considerations
I/O Runtime has passed the Adobe Asset team scrutiny in order to reach GA and be used as a serverless environment in a multi-tenancy way. There are also ongoing security audits and pen tests that continuously check the platform security.
The platform is CCF compliant and GDPR-ready (in that, we don’t keep any user logs or results more than 30-days). Some of the key features that make our platform secure:
- Developer code is executed in a docker container. A container is never reused across different tenants. If it is reused, it is for the same tenant and the same action
- The developer code is encrypted
- Developer code is deployed in a namespace. A namespace is not shared, a tenant owns a namespace. Each namespace has a unique key that is used for encrypting the code
The Future is Bright - Cloud Native Applications
Our group is working on a set of technologies (CLI, debugging tools, IDE plugin, storage, CDN integration, API wrappers) that can be used to create a full stack application (Single Page Application + Backend) that is powered by I/O Runtime + CDN – so there is no need to spin up a server in order to create a full application.
While we will unleash the full power of this new platform early next year, there are already pieces that can be used today to build Runtime applications faster:
- Adobe I/O CLI with Runtime Plugin - GitHub repo
- Authentication library - GitHub repo
- Project Starter - GitHub repo
Next Steps
I/O Runtime fully delivers on the serverless promise, but success requires developers to be aware of, and employ, serverless best practices.
At the same time, this is just the beginning for Adobe I/O Runtime and you are encouraged to help enhance the platform and help to guide its future. The following sections provide multiple ways for you to engage with the Adobe I/O Runtime team and suggest improvements to the platform and its documentation.
Social media
You can follow the Adobe I/O team on Twitter, Medium, and Youtube.
Support
If you have issues with Adobe I/O Runtime, you can use the Adobe I/O Runtime Forum.
If you have issues with the documentation, you can submit a pull request through the Adobe I/O Runtime GitHub repository.
You can also check the FAQ for answers to some of the most common questions.